شروع کار با یادگیری ماشینی
از برنامه های ترجمه گرفته تا وسایل نقلیه خودران، همه قدرت ها با یادگیری ماشینی. راهی برای حل مسائل و پاسخ به سوالات پیچیده ارائه می دهد. این اساساً فرآیند آموزش یک نرم افزار به نام الگوریتم یا مدل است تا پیش بینی های مفیدی از داده ها انجام دهد. این مقاله مقولههای مشکلات یادگیری ماشین و اصطلاحات مورد استفاده در زمینه یادگیری ماشین را مورد بحث قرار میدهد.
انواع مشکلات یادگیری ماشین
روش های مختلفی برای طبقه بندی مشکلات یادگیری ماشین وجود دارد. در اینجا، ما واضح ترین آنها را مورد بحث قرار می دهیم
1. بر اساس ماهیت “سیگنال” یا “بازخورد” یادگیری موجود برای یک سیستم یادگیری
- یادگیری نظارت شده : مدل یا الگوریتم با ورودی های نمونه و خروجی های مورد نظر آنها ارائه می شود و سپس الگوها و ارتباطات بین ورودی و خروجی را پیدا می کند. هدف یادگیری یک قانون کلی است که ورودی ها را به خروجی ها نگاشت می کند. فرآیند آموزش تا زمانی ادامه می یابد که مدل به سطح مطلوبی از دقت در داده های آموزشی دست یابد. برخی از نمونه های واقعی عبارتند از:
- طبقه بندی تصویر: شما با تصاویر/برچسب ها تمرین می کنید. سپس در آینده، تصویر جدیدی ارائه میدهید که انتظار میرود کامپیوتر شی جدید را تشخیص دهد.
- پیشبینی بازار/رگرسیون: کامپیوتر را با دادههای تاریخی بازار آموزش میدهید و از رایانه میخواهید که قیمت جدید را در آینده پیشبینی کند.
- یادگیری بدون نظارت : هیچ برچسبی به الگوریتم یادگیری داده نمی شود و آن را به تنهایی برای یافتن ساختار در ورودی خود رها می کند. برای خوشه بندی جمعیت ها در گروه های مختلف استفاده می شود. یادگیری بدون نظارت می تواند به خودی خود یک هدف باشد (کشف الگوهای پنهان در داده ها).
- خوشه بندی: شما از رایانه می خواهید که داده های مشابه را به خوشه ها تفکیک کند، این در تحقیق و علم ضروری است.
- تصویرسازی با ابعاد بالا: از رایانه برای کمک به تجسم داده های با ابعاد بالا استفاده کنید.
- مدل های مولد: پس از اینکه یک مدل توزیع احتمال داده های ورودی شما را دریافت کرد، می تواند داده های بیشتری تولید کند. این می تواند برای قوی تر کردن طبقه بندی کننده شما بسیار مفید باشد.
نمودار ساده ای که مفهوم یادگیری تحت نظارت و بدون نظارت را پاک می کند در زیر نشان داده شده است:
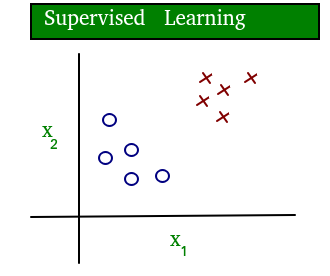
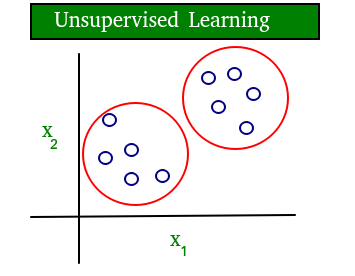
همانطور که به وضوح می بینید، داده ها در یادگیری نظارت شده دارای برچسب هستند، در حالی که داده های یادگیری بدون نظارت بدون برچسب هستند.
- یادگیری نیمه نظارتی : مشکلاتی که در آنها مقدار زیادی داده ورودی دارید و فقط برخی از داده ها برچسب گذاری می شوند، مسائل یادگیری نیمه نظارت شده نامیده می شوند. این مشکلات بین یادگیری تحت نظارت و بدون نظارت قرار می گیرند. به عنوان مثال، یک آرشیو عکس که در آن فقط برخی از تصاویر دارای برچسب هستند (به عنوان مثال سگ، گربه، شخص) و اکثریت بدون برچسب هستند.
- یادگیری تقویتی : یک برنامه کامپیوتری با یک محیط پویا تعامل دارد که در آن باید هدف خاصی را انجام دهد (مانند رانندگی وسیله نقلیه یا انجام یک بازی در برابر حریف). این برنامه بازخوردهایی را از نظر پاداش و تنبیه ارائه می کند که در فضای مشکل خود حرکت می کند.
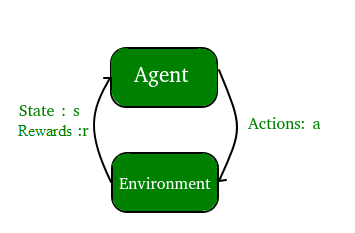
2. دو مورد از رایج ترین موارد استفاده از یادگیری تحت نظارت عبارتند از:
- طبقهبندی : ورودیها به دو یا چند کلاس تقسیم میشوند و یادگیرنده باید مدلی تولید کند که ورودیهای دیده نشده را به یک یا چند کلاس (طبقهبندی چند برچسبی) از این کلاسها اختصاص دهد و پیشبینی کند که آیا چیزی به یک کلاس خاص تعلق دارد یا نه. این معمولاً به روشی تحت نظارت حل می شود. مدلهای طبقهبندی را میتوان در دو گروه دستهبندی باینری و طبقهبندی چند کلاسه دستهبندی کرد. فیلتر کردن هرزنامه نمونهای از طبقهبندی باینری است، که در آن ورودیها پیامهای ایمیل (یا دیگر) و کلاسها «هرزنامه» و «نه هرزنامه» هستند.
- رگرسیون : همچنین یک مسئله یادگیری نظارت شده است که یک مقدار عددی را پیش بینی می کند و خروجی ها به جای گسسته پیوسته هستند. به عنوان مثال، پیش بینی قیمت سهام با استفاده از داده های تاریخی.
نمونه ای از طبقه بندی و رگرسیون در دو مجموعه داده مختلف در زیر نشان داده شده است: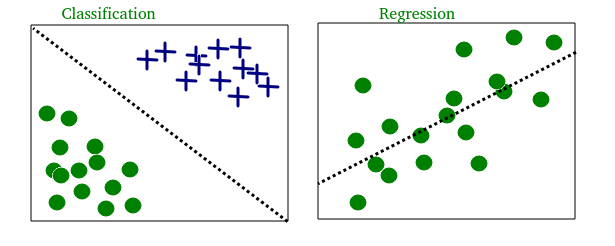
3. رایج ترین یادگیری های بدون نظارت عبارتند از:
- خوشه بندی : در اینجا مجموعه ای از ورودی ها به گروه ها تقسیم می شوند. برخلاف طبقهبندی، گروهها از قبل شناخته شده نیستند، و این امر معمولاً یک کار بدون نظارت است. همانطور که در مثال زیر می بینید، نقاط داده داده شده به گروه هایی تقسیم شده اند که با رنگ های قرمز، سبز و آبی قابل شناسایی هستند.
- تخمین چگالی : وظیفه یافتن توزیع ورودی ها در فضایی است.
- کاهش ابعاد : ورودی ها را با نگاشت آنها در فضایی با ابعاد کمتر ساده می کند. مدلسازی موضوع یک مشکل مرتبط است، جایی که به یک برنامه فهرستی از اسناد زبان انسانی داده میشود و وظیفه دارد بفهمد کدام اسناد موضوعات مشابه را پوشش میدهند.
بر اساس این وظایف/مشکلات یادگیری ماشین، تعدادی الگوریتم داریم که برای انجام این کارها استفاده می شود. برخی از الگوریتمهای رایج یادگیری ماشین عبارتند از: رگرسیون خطی، رگرسیون لجستیک، درخت تصمیم، SVM (ماشینهای بردار پشتیبانی)، Naive Bayes، KNN (K نزدیکترین همسایگان)، K-Means، Random Forest و غیره. توجه: همه این الگوریتمها پوشش داده خواهند شد . در مقالات آینده
اصطلاحات یادگیری ماشینی
- مدل A یک نمایش خاص است که از داده ها با اعمال برخی از الگوریتم های یادگیری ماشین یاد می شود. به یک مدل، فرضیه نیز گفته می شود .
- ویژگی یک ویژگی یک ویژگی قابل اندازه گیری فردی از داده های ما است. مجموعه ای از ویژگی های عددی را می توان به راحتی با یک بردار ویژگی توصیف کرد . بردارهای ویژگی به عنوان ورودی به مدل تغذیه می شوند. به عنوان مثال، برای پیشبینی یک میوه، ممکن است ویژگیهایی مانند رنگ، بو، طعم و غیره وجود داشته باشد. توجه: انتخاب ویژگیهای آموزنده، متمایز و مستقل گامی حیاتی برای الگوریتمهای مؤثر است. ما معمولاً از یک استخراج کننده ویژگی برای استخراج ویژگی های مربوطه از داده های خام استفاده می کنیم.
- Target (Label) یک متغیر یا برچسب هدف مقداری است که باید توسط مدل ما پیشبینی شود. برای مثال میوه مورد بحث در بخش ویژگی ها، برچسب با هر مجموعه ورودی نام میوه مانند سیب، پرتقال، موز و غیره خواهد بود.
- آموزش ایده ارائه مجموعهای از ورودیها (ویژگیها) و خروجیهای مورد انتظار آن (برچسبها) است، بنابراین پس از آموزش، مدلی (فرضیه) خواهیم داشت که سپس دادههای جدید را به یکی از دستههای آموزشدیده ترسیم میکند.
- پیشبینی هنگامی که مدل ما آماده شد، میتوان مجموعهای از ورودیها را تغذیه کرد که یک خروجی (برچسب) پیشبینیشده را به آنها ارائه میدهد. اما مطمئن شوید که اگر دستگاه روی دادههای دیده نشده عملکرد خوبی داشته باشد، فقط ما میتوانیم بگوییم که دستگاه عملکرد خوبی دارد.
شکل زیر مفاهیم فوق را پاک می کند: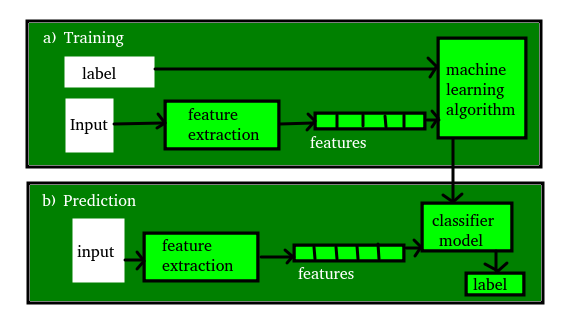
برای شروع یادگیری ماشینی مراحل زیر وجود دارد:
-
تعریف مشکل : مشکلی را که می خواهید حل کنید شناسایی کنید و تعیین کنید که آیا یادگیری ماشینی می تواند برای حل آن استفاده شود یا خیر.
-
جمع آوری داده ها : داده هایی را که برای آموزش مدل خود استفاده خواهید کرد جمع آوری و پاک کنید. کیفیت مدل شما به کیفیت داده های شما بستگی دارد.
-
کاوش در داده ها: برای درک ساختار و روابط درون داده های خود از روش های تجسم داده و آماری استفاده کنید.
-
پیش پردازش داده ها : داده ها را برای مدل سازی با عادی سازی، تبدیل و پاکسازی در صورت لزوم آماده کنید.
-
تقسیم داده ها : داده ها را به مجموعه داده های آموزشی و آزمایشی تقسیم کنید تا مدل خود را تأیید کنید.
-
انتخاب یک مدل : مدل یادگیری ماشینی را انتخاب کنید که برای مشکل شما و داده هایی که جمع آوری کرده اید مناسب باشد.
-
آموزش مدل: از داده های آموزشی برای آموزش مدل استفاده کنید و پارامترهای آن را به گونه ای تنظیم کنید که تا حد امکان با داده ها مطابقت داشته باشد.
-
ارزیابی مدل: از داده های آزمون برای ارزیابی عملکرد مدل و تعیین دقت آن استفاده کنید.
-
تنظیم دقیق مدل: بر اساس نتایج ارزیابی، مدل را با تنظیم پارامترهای آن و تکرار فرآیند آموزش تا رسیدن به سطح دقت مطلوب، تنظیم دقیق کنید.
-
استقرار مدل: مدل را در برنامه یا سیستم خود ادغام کنید و آن را برای استفاده دیگران در دسترس قرار دهید.
-
نظارت بر مدل: به طور مداوم بر عملکرد مدل نظارت کنید تا مطمئن شوید که نتایج دقیق در طول زمان ارائه می شود.
مثال :
در اینجا یک مثال ساده برای یادگیری ماشینی در پایتون وجود دارد که نشان می دهد چگونه می توان مدلی را برای پیش بینی گونه های گل زنبق بر اساس اندازه گیری های کاسبرگ و گلبرگ آنها آموزش داد:
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
df = pd.read_csv('iris.csv')
X = df[['sepal_length', 'sepal_width', 'petal_length', 'petal_width']]
y = df['species']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
model = SVC()
model.fit(X_train, y_train)
accuracy = model.score(X_test, y_test)
print('Test accuracy:', accuracy)
|
خروجی:
دقت تست: 0.9666666666666667